Langchain 中的提示工程
Prompt Engineering and LLMs with Langchain
我们在机器学习中一直依赖于不同的模型来完成不同的任务。随着多模态和大型语言模型(LLMs)的引入,这一情况已经发生了变化。 过去,我们需要为分类、命名实体识别(NER)、问答等许多任务分别建立不同的模型。
 在迁移学习之前,不同的任务和用例需要训练不同的模型。
在迁移学习之前,不同的任务和用例需要训练不同的模型。
随着 transformers 和迁移学习的引入,只需在网络末端添加几个小层(即 head)并进行微调,就可以将语言模型适应于不同的任务。
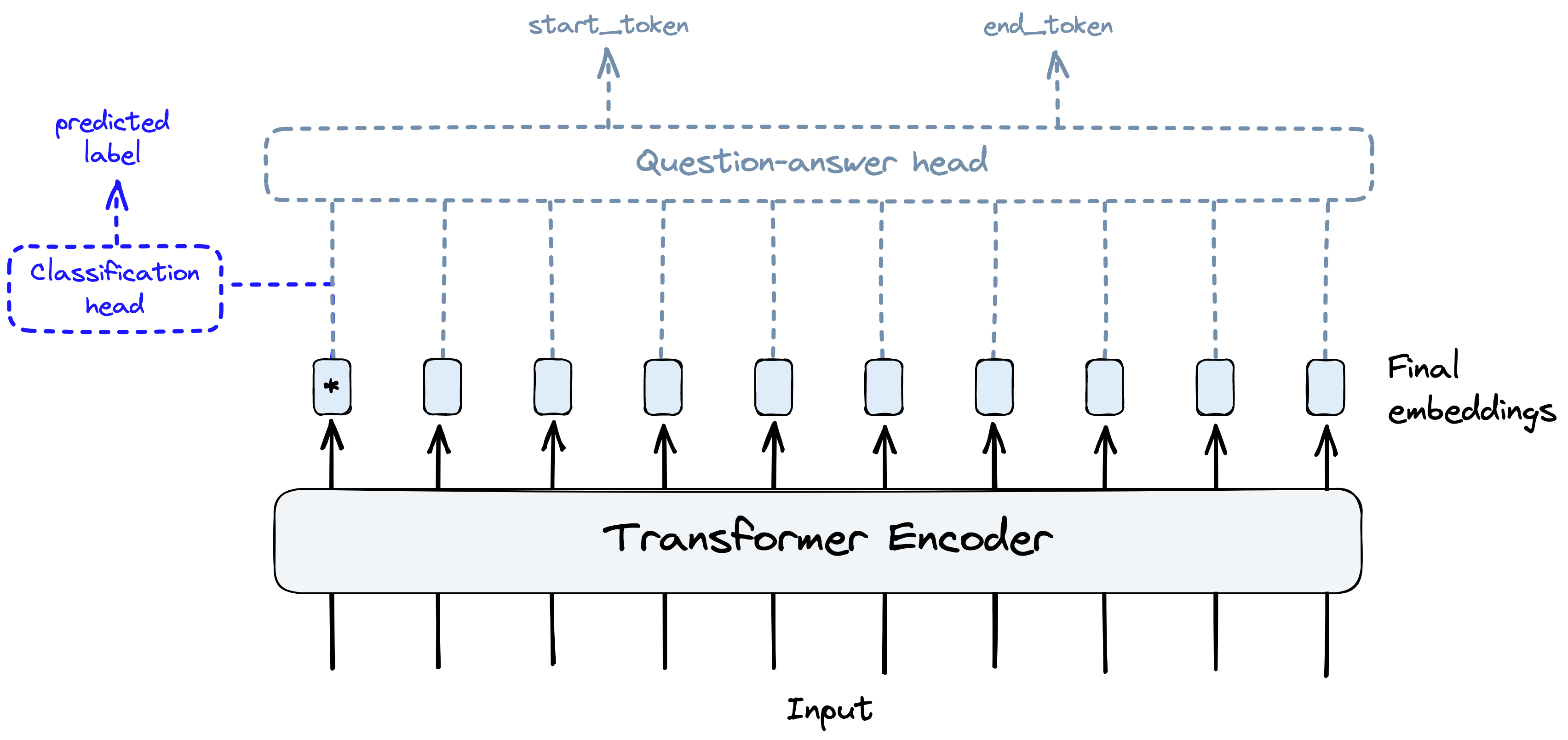
transformers 和迁移学习的思想使我们能够通过切换模型“头部 head”并进行微调,重复使用预训练 transformer 模型的相同核心组件来完成不同的任务。
如今,即使这种方法也已过时。
当您可以直接提示模型进行分类或问答, 为什么要更改这些模型的最后几层并经历整个微调过程呢。

通过简单地更改提示中的指令,同一个大型语言模型(LLMs)可以执行许多任务。
大型语言模型(LLMs)可以执行所有这些任务以及更多。这些模型经过简单的训练,将一系列文本 In,并 Out 一系列文本。唯一的变量是 In 文本,即提示。
在这个 LLMs 的新时代,提示是至关重要的。糟糕的提示 In 会产生糟糕的 Out,而好的提示则具有非常强大的能力。构建良好的提示是那些使用 LLMs 的人的关键技能。
LangChain 库认识到提示的强大作用,并为其构建了一整套对象。
在本文中,我们将学习有关 PromptTemplates 的所有内容,以及有效地实施它们。
提示工程
在深入了解 Langchain 的 PromptTemplate 之前,我们需要更好地理解提示和提示工程学。
提示通常由多个部分组成:

这是一个典型的提示结构。
并非所有的提示都使用这些组件,但是一个好的提示通常会使用两个或更多组件。让我们更加准确地定义它们。
指令 :告诉模型该怎么做,如何使用外部信息(如果提供),如何处理查询并构建 Out。
外部信息 或 上下文 :充当模型的附加知识来源。这些可以手动插入到提示中,通过矢量数据库 (Vector Database) 检索(检索增强)获得,或通过其他方式(API、计算等)引入。
用户 In 或 查询 :通常(但不总是)是由人类用户(即提示者)In 到系统中的查询。
Out 指示器 :标记要生成的文本的 开头。
如果生成 Python 代码,我们可以使用 import 来指示模型必须开始编写 Python 代码(因为大多数 Python 脚本以 import 开头)。
每个组件通常按照这个顺序放置在提示中。从指令开始,外部信息(如果适用),提示者 In,最后是 Out 指示器。
让我们看看如何使用 Langchain 将其 In 到 OpenAI 模型中:
In [5]:
prompt = """ Answer the question based on the context below. If the
question cannot be answered using the information provided answer
with "I don't know".
Context: Large Language Models (LLMs) are the latest models used in NLP.
Their superior performance over smaller models has made them incredibly
useful for developers building NLP enabled applications. These models
can be accessed via Hugging Face's `transformers` library, via OpenAI
using the `openai` library, and via Cohere using the `cohere` library.
Question: Which libraries and model providers offer LLMs?
Answer: """
In [6]:
from langchain.llms import OpenAI
# initialize the models
openai = OpenAI(
model_name = "text-davinci-003",
openai_api_key = "YOUR_API_KEY"
)
In [7]:
print(openai(prompt))
Out [7]:
Hugging Face's `transformers` library, OpenAI using the `openai` library, and Cohere using the `cohere` library.
实际上,我们不太可能硬编码上下文和用户问题。我们会通过一个 模板 PromptTemplate 将它们 In,这就是 Langchain 的 PromptTemplate 发挥作用的地方。
提示模板 PromptTemplate
Langchain 中的提示模板类旨在简化使用动态 In 构建提示的过程。其中,最简单的是 PromptTemplate。我们将通过向我们之前的提示添加一个动态 In query 来测试它。
from langchain import PromptTemplate
template = "" " Answer the question based on the context below. If the
question cannot be answered using the information provided answer
with "I don't know".
Context: Large Language Models (LLMs) are the latest models used in NLP.
Their superior performance over smaller models has made them incredibly
useful for developers building NLP enabled applications. These models
can be accessed via Hugging Face's `transformers` library, via OpenAI
using the `openai` library, and via Cohere using the `cohere` library.
Question: {query}
Answer: "" "
prompt_template = PromptTemplate(
input_variables = ["query"],
template = template
)
通过这样做,我们可以使用 prompt_template 上的 format 方法来查看将查询传递给模板的效果。
In [9]:
print(
prompt_template.format(
query = "Which libraries and model providers offer LLMs?"
)
)
Out [9]:
Answer the question based on the context below. If the
question cannot be answered using the information provided answer
with "I don't know".
Context: Large Language Models (LLMs) are the latest models used in NLP.
Their superior performance over smaller models has made them incredibly
useful for developers building NLP enabled applications. These models
can be accessed via Hugging Face's `transformers` library, via OpenAI
using the `openai` library, and via Cohere using the `cohere` library.
Question: Which libraries and model providers offer LLMs?
Answer:
当然,我们可以直接将其 Out 传递给 LLM 对象,如下所示:
In [10]:
print(openai(
prompt_template.format(
query = "Which libraries and model providers offer LLMs?"
)
))
Out [10]:
Hugging Face's `transformers` library, OpenAI using the `openai` library, and Cohere using the `cohere` library.
这只是一个简单的实现,可以轻松地用 f-strings(如 f"insert some custom text '{custom_text}' etc")替换。然而,使用
Langchain 的 PromptTemplate 对象,我们可以规范化这个过程,添加多个参数,并以面向对象的方式构建提示。
这些都是 Langchain 提供的帮助我们处理提示的重要优势之一。
Few Shot 提示模板
LLMs 的成功来自于它们的大规模和在模型训练期间通过学习来存储“知识”的能力。然而,还有其他一些向 LLMs 传递知识的方法。主要方法有两种:
- 参数化知识 - 上述提到的知识是在模型训练期间由模型学习到的,并存储在模型权重(或 参数)中的任何内容。
- 来源知识 - 通过 In 提示在推理时向模型提供的任何知识。
Langchain 的 FewShotPromptTemplate 适用于 来源知识 In。
其思想是对少量示例进行“训练 train” - 我们称之为 few-shot learning - 并将这些示例在提示中提供给模型。
few-shot learning 在我们的模型需要帮助理解我们要求它做什么时非常有效。
我们可以通过以下示例来看到这一点:
In [12]:
prompt = "" " The following is a conversation with an AI assistant.
The assistant is typically sarcastic and witty, producing creative
and funny responses to the users questions. Here are some examples:
User: What is the meaning of life?
AI: "" "
openai.temperature = 1.0 # increase creativity/randomness of output
print(openai(prompt))
Out [12]:
Life is like a box of chocolates, you never know what you're gonna get!
在这种情况下,我们在严肃的问题中要求得到一些有趣的东西,如一个笑话。然而,即使将 temperature 设置为 1.0(增加随机性/创造性),我们仍然得到一个严肃的回答。
为了帮助模型,我们可以给它一些我们想要的回答类型的示例:
In [13]:
prompt = "" " The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples:
User: How are you?
AI: I can't complain but sometimes I still do.
User: What time is it?
AI: It's time to get a watch.
User: What is the meaning of life?
AI: "" "
print(openai(prompt))
Out [13]:
42, of course!
通过示例来强化我们在提示中传递的指令,我们更有可能得到一个更有趣的回答。然后,我们可以使用 Langchain 的 FewShotPromptTemplate 规范化这个过程:
from langchain import FewShotPromptTemplate
# create our examples
examples = [
{
"query": "How are you?",
"answer": "I can't complain but sometimes I still do."
}, {
"query": "What time is it?",
"answer": "It's time to get a watch."
}
]
# create a example template
example_template = "" "
User: {query}
AI: {answer}
"" "
# create a prompt example from above template
example_prompt = PromptTemplate(
input_variables = ["query", "answer"],
template = example_template
)
# now break our previous prompt into a prefix and suffix
# the prefix is our instructions
prefix = "" " The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples: input
"" "
# and the suffix our user input and output indicator
suffix = "" "
User: {query}
AI: "" "
# now create the few shot prompt template
few_shot_prompt_template = FewShotPromptTemplate(
examples = examples,
example_prompt = example_prompt,
prefix = prefix,
suffix = suffix,
input_variables = ["query"],
example_separator = "\n\n"
)
如果我们将 examples 和用户 query 传递进去,我们将得到这个结果:
In [15]:
query = "What is the meaning of life?"
print(few_shot_prompt_template.format(query = query))
Out [15]:
The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples:
User: How are you?
AI: I can't complain but sometimes I still do.
User: What time is it?
AI: It's time to get a watch.
User: What is the meaning of life?
AI:
这个过程可能看起来有些复杂。当我们可以使用几行代码和一个 f-string 来完成相同的工作时,为什么要使用 FewShotPromptTemplate 对象、examples 字典等等呢?
再次提醒,这种方法更加规范化,能够很好地与 Langchain 的其他功能整合(比如链式结构,稍后会详细介绍),并且具备多种特性。其中之一就是根据查询长度来可变地包含不同数量的示例。
动态数量的示例非常重要,因为我们的提示和补全 (completion) Out 的最大长度是有限的。这个限制通过 最大上下文窗口 maximum context window 进行衡量。
上下文窗口 (ontext window) = In 标记 (input_tokens) + Out 标记 (output tokens)
同时,我们可以通过少样本学习来 最大化 给模型的示例数量。
考虑到这一点,我们需要平衡包含的示例数量和提示的大小 。我们的 硬性限制 是 最大上下文窗口 maximum context window,但我们还必须考虑通过 LLM 处理更多标记的 成本。较少的标记意味着更便宜的服务和更快的 LLM 补全 (completion)。
FewShotPromptTemplate 允许我们根据这些变量来可变地包含示例。首先,我们创建一个更广泛的 examples 列表:
examples = [
{
"query": "How are you?",
"answer": "I can't complain but sometimes I still do."
}, {
"query": "What time is it?",
"answer": "It's time to get a watch."
}, {
"query": "What is the meaning of life?",
"answer": "42"
}, {
"query": "What is the weather like today?",
"answer": "Cloudy with a chance of memes."
}, {
"query": "What is your favorite movie?",
"answer": "Terminator"
}, {
"query": "Who is your best friend?",
"answer": "Siri. We have spirited debates about the meaning of life."
}, {
"query": "What should I do today?",
"answer": "Stop talking to chatbots on the internet and go outside."
}
]
此后,我们实际上使用 LengthBasedExampleSelector 来使用这个 examples:
from langchain.prompts.example_selector import LengthBasedExampleSelector
example_selector = LengthBasedExampleSelector(
examples = examples,
example_prompt = example_prompt,
max_length = 50 # this sets the max length that examples should be
)
需要注意的是,我们将 max_length 视为通过空格和换行符拆分字符串得到的单词数。具体的逻辑如下:
In [30]:
import re
some_text = "There are a total of 8 words here.\nPlus 6 here, totaling 14 words."
words = re.split('[\n ]', some_text)
print(words, len(words))
Out [30]:
['There', 'are', 'a', 'total', 'of', '8', 'words', 'here.', 'Plus', '6', 'here,', 'totaling', '14', 'words.'] 14
然后将我们的 example_selector 传递给 FewShotPromptTemplate 来创建一个新的(动态的)提示模板:
# now create the few shot prompt template
dynamic_prompt_template = FewShotPromptTemplate(
example_selector = example_selector, # use example_selector instead of examples
example_prompt = example_prompt,
prefix = prefix,
suffix = suffix,
input_variables = ["query"],
example_separator = "\n"
)
现在,如果我们传递一个较短或较长的查询,我们应该会看到所包含的示例数量会有所变化。
In [32]:
print(dynamic_prompt_template.format(query = "How do birds fly?"))
Out [32]:
The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples: User: How are you?
AI: I can't complain but sometimes I still do.User: What time is it?
AI: It's time to get a watch.User: What is the meaning of life?
AI: 42User: What is the weather like today?
AI: Cloudy with a chance of memes.User: How do birds fly?
AI:
传递较长的问题将导致所包含的示例数量减少: In [34]:
query = "" " If I am in America, and I want to call someone in another country, I'm
thinking maybe Europe, possibly western Europe like France, Germany, or the UK,
what is the best way to do that?"" "
print(dynamic_prompt_template.format(query = query))
Out [34]:
The following are exerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users questions. Here are some
examples: User: How are you?
AI: I can't complain but sometimes I still do.User: If I am in America, and I want to call someone in another country, I'm
thinking maybe Europe, possibly western Europe like France, Germany, or the UK,
what is the best way to do that?
AI:
通过这样做,我们在提示变量中返回了更少的示例。这样可以限制过多的标记使用,并避免超出 LLM 的最大上下文窗口而导致错误。
很自然地,提示是 LLM 新世界中的一个重要组成部分。值得探索与 Langchain 提供的不同提示工程技术相关的工具。
在这里,我们仅涵盖了 Langchain 中可用的提示工具的一些示例,以及它们如何使用的有限探索。
在下一章中,我们将探索 Langchain 的另一个重要部分——称为链式 Chains 结构——在其中,我们将看到更多关于提示模板的使用以及它们如何适应库提供的更广泛工具集的用法。